

In about 5 years from now, 2024, the world population is expected to be around 8 billion. Now, not all of that 8 billion will be using natural language processing (NLP)-enabled services, but this is a good base to begin to evaluate the potential impact and value of a hypothetical single layer ecosystem model supporting a conversational natural language understanding support system.
I know, that was a lot of words. Let’s drill into just what all this might mean.
Why 2024, and why go through this analysis?
Great questions.
First, why go through this analysis? Within the discipline of artificial intelligence (AI), building machine and deep learning (ML & DL) neural nets to solve problems, there is a hard constraint referred to as generalization. Neural networks are designed to learn from a set of training data. The training data represents the pattern the neural net should recognize when fed new data. Typically that training data is constrained to a specific problem or goal. Think of the problem or goal as being more or less well defined, the pattern noted above, depending on the complexity of the deep learning neural net. The pattern is the context.
The problem is that life is not so well defined. Our minds are able to comprehend a much broader set of concurrent events, and then more or less determine which of those concurrent events needs to rise to the level of focus and action. An AI model has one problem, one pattern to solve for and is not concerned with the outer world that its problem exists within, hence the “generalization problem.” Neural nets do not generalize. They solve well-defined, constrained, what are effectively pattern matching problems.
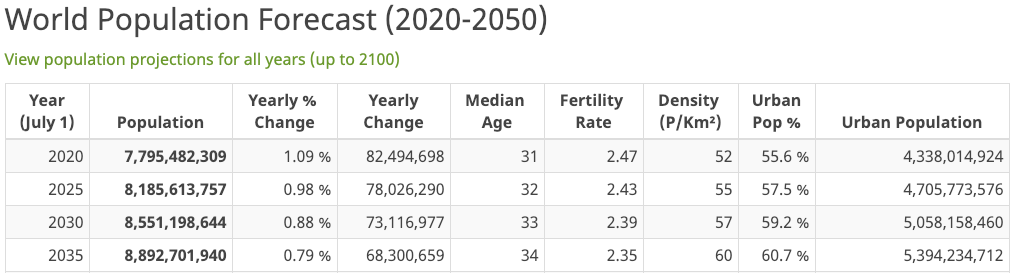
Within the AI space, there are processor challenges, data challenges, trend challenges, and language challenges. This investigation focuses on language challenges. Within the AI language generation space, there are a number of sub-areas, like natural language understanding (NLU), natural language processing (NLP), and natural language generation (NLG). The problem is that when we talk, our brains contain a set of concurrent processes supporting thought. At one moment, the tip of those processes might be focused on a singular task, like choosing which song to listen to next. What would follow is an action toward selecting the song we landed on. That action might take the form of “Alexa, play 1999 by Charli XCX & Troye Sivan.” And then your thought might pick back up some other thread, perhaps that special person and last night.
The point is that our ever active minds are not solely constrained to command driven articulations, the type that NLP solutions are designed for.
For the remainder of this exploration, I will use Alexa as an example since most of us are aware of it. The problem, though, is not constrained to Alexa. The problem is pervasive across the AI natural language understanding space, think chatbots and providers like CaptialOne, Hugging Face and others, which is the reason an underlying ecosystem solution might be valuable.
And therein lies the user experience gap. Once we start talking to someone or something like Alexa, our minds are engaged, and we begin to be who we are, a continuous thought and expression entity. So right after we say “Alexa, play 1999 by Charli XCX,” our conversation with Alexa might go something like, “Alexa, what do you think about what happened last night?” Alexa has absolutely no context for where that second string (sentence) it just heard came from within its command-driven training. How will Alexa respond? And this is the problem that NLP consumers, you and I, experience almost every day to some greater or lesser extent with computer-generated conversational systems.
When new and unusual sentences are sent to an NLP system like Alexa, they just don’t know how to respond. The internet is full of Alexa silly response examples. Yet, Alexa is learning with each of these new sentences. With each new set of conversational strings that Alexa doesn’t know how to respond to, Alexa learns something, or the data is stored for analysis so that next time that or something like that sentence is issued, Alexa can respond with something that makes some type of sense. Again, the problem is that Alexa is learning at its customer experience expense. And this is a big deal.
For Alexa, the problem is much worse than you might expect. Why? Because in its current implementation Alexa will always be constrained to the conversational strings issued by its consumers, a very small subset of the world and possible human articulations, and hence possible learning conversational strings. This means that Alexa, in its current implementation, to some greater or lesser extent will be learning a lot into the distant future (and the providers of Alexa have the data to determine how extensive this user experience problem is). How big is that potential issue today? There are:
Amazon has finally revealed how many Alexa devices have been sold.
So if only 1/100 of the commands issued to Alexa today stream off into some conversation that Alexa doesn’t understand, like the above “Alexa, what do you think about what happened last night?”, that’s still 1 million not so good customer experiences for Alexa at whatever rate those 100 million devices get used. My guess would be that as its customer base grows, the Alexa team would want to do everything it could to reduce that not-so-good experience ratio — that happens to exist because of the constraints of the underlying functionality of Alexa. Alexa’s training is constrained to what it has, what is knows, not what it doesn’t know — the generalization problem.
The answer to “why go through this analysis?” is to investigate a possible improved customer experience where conversations with NLP systems exceed the NLP training data, to evaluate a possible ecosystem option for providing improved customer experience outcomes.
Why 2024? Because if an entity were to start enabling a generalization ecosystem infrastructure today, an infrastructure intended to span and support the NLP, NLG, NLU providers, it would take the first year to obtain an initial customer and build out a baseline minimum viable product (MVP). By the end of year two, the hypothetical entity would be expected to have established a scalable service model and start to grow its customer base. By year three through five, the hypothetical entity would be expected to execute on its charter, a broad ecosystem-based natural language understanding solution for those conversations which exceed the individual providers training set. So, by the year 2024, we would expect a reasonable customer base that would substantiate the charter for an ecosystem model.
How many conversations might that be in 2024? How big would this entity be expected to scale to, some portion of the total addressable NLP market?
Let’s arrive at some estimate of NLP customers whose experience would be improved with a generalization solution. Per the graphic above, if there are expected to be around 8 billion people in 2024, and roughly 4.5 billion of those are in urban areas. Let’s guess by 2024 most of that urban population would have an opportunity to engage with an NLP interface at some point in their day. Just for argument’s sake, let’s say that half of our global rural 3.5 billion also interact with an NLP-backed solution at some point in their day. That is, there will be some subset of the rural population that will not have access to modern technology. In this model, arguably open to refinement, our total addressable population of NLP customers per day in 2024 might possibly be around 6.25 billion.
Most of the 6.25 billion people interacting with NLP-based systems will issue the “command” and obtain their result without any misunderstandings. Yet, there will be a subset that will fall into our above scenario. How many of that 6.25 billion population might follow the scenario above, where they start communicating with an NLP-based service and say or type something not within the training context of the NLP system on the other side of their communication exchange?
Let’s see if we can roughly arrive at a per day usage model in order to determine some idea of the demand for a service that provides a “generalization” service. We’ll start with a day because the demand, the number of people per day, is easy to multiply by 360 with some fudge factors to get a per year number.
Of these 6.25 billion people interacting with NLP systems, there will be a subset with the Alexa-type voice and chatbot types of conversation services. Just to be conservative, let’s guess that only 10 percent of the NLG responses are the Alexa and chatbot type, or 626 million people engaging with Alexa-type of voice-enabled systems or chatbots, of which let’s say just to establish a baseline, 1/100 of those interactions exceed the AI training (resulting in a less than desirable customer experience). People like to play games with the “Alexas” of the world and like to talk about things only they have the context for. Based on human behavior patterns it seems reasonable that the real percentage would migrate north of 1%. Time and data will determine the real number. For now, 1% reduces our ecosystem support model to a total addressable market of 6.25 million people within the period of a day.
And that’s if conversations with the Alexas of the world and chatbots happened only once per customer across the course of a day. In reality, there would be some multiplier used in the above to represent the average number of customer engagements across the course of the day. For example, Alexa might have three customer engagements/commands in the morning, and four in the afternoon and evening, for a total of 7 Alexa interactions plus the one chatbot conversation with the bank, and perhaps one with their internet provided, or power provider, or… By 2024 there will be a number of NLP supported experiences we engage with across the day. The point is that the above NLP interaction quantity of 6.25 million underrepresents the total addressable market for an NLP conversation support service across a day in 2024.
So, we need a multiplier to represent some total hypothetical NLP experiences that exceed the systems training data, within a day. We’ve established that interaction with NLP systems across the day will probably be more than once. For brevity of time, let’s pick 2 as the multiplier just as a starting point because we know it’s larger than 1 due to the average number of NLP interactions across a day. This number will get refined with data and time. Remember, this is only for the 1/100 of NLP customers using NLP systems where the human response exceeds the NLP training. So, just to have something to start with as a baseline, in 2024, an estimated 6.25 million times 2, or 12.5 million NLP customer experiences per day could possibly be not so good, in that the human part of the exchange will exceed the training data of the NLP system.
Why would anyone want to invest in providing an ecosystem-based generalization solution service to address this potential 12.5 million customer need? Let’s follow the hypothetical 2024 money.
Our hypothetical service revenue model, per day, might look something like (at, say, three pennies per request from Alexa or chatbot service for context help):
Revenue per day (.03 x 12.5 M)= $375,000
Or, per year, $136,875,000
And this is just to establish a possible revenue stream for providing the ecosystem solution to ask, “does an NLP ecosystem generalization solution seem reasonable?”
For 100 million + Alexa devices, let’s say only 1/100 of those customer interactions exceeded the Alexa training set or 1 million not-so-good customer experiences, let’s say per day, assuming all those Alexa devices are being used at some point across the day. In those cases, if the Alexa service had an API it could access which would provide an improved context value for the conversation with which it could then provide an improved response, it would cost the Alexa service three cents to provide that improved customer experience, and then add that response to its library. A three-cent re-usable solution sounds like a good investment for the Alexa team. Not to worry, there are plenty of other unanticipated human utterances not in Alexa’s library right around the corner. And that’s the wonderful thing about this model, the human thought process is constantly generating new ways of saying something.
Consider one final thought. As we progress down this AI path with improving AI architectures, increasingly powerful processing capabilities (witness qubit processing), neuroscience advancements, and increasing business consumption of AI-based services and solutions, there seems to be an agreed to inevitability of these trend toward an artificial general intelligence, or AGI, at some point in the distant future. If you agree with the trends and agree with some type of AGI inevitability, then the resulting AGI will continue to grow, becoming an artificial superintelligence or ASI. The thought to consider is that as this current trend continues from AI toward AGI, a human-centric path where AI solutions integrate the human component, like the generalization solution outlined here, is preferable to one entirely replacing humans.