

Music seems to be one of the fields that, at a surface level at least, AI just can’t seem to penetrate. AI is rapidly taking over so many fields, and there’s huge progress in music too! There are so many awesome developments (check out the app Transformer) and progress is moving at a breakneck pace.
So what’s the problem?
Why aren’t these being used?
There are so many creative tools that would be amazing for any composer, but musicians just aren’t! Despite some imperfections, these tools provide huge amounts of creative material; but there’s simply no one to use it.
How can there possibly be a shortage of musicians?
You’re right. There isn’t. The shortage exists in musicians who have the technical skill necessary to use these tools — the barrier to entry is too high. In order to use anything beyond the very basic tools, the user (let’s call him Sam) is required to know Python, already cutting off any non-programmers. Sam also needs to go through the harrowing installation and setup of Python and its dependencies (as well as an IDE) and the complex web of installations for the Magenta module to work.
Sam is all done combing through Stack Overflow and gets rid of all the
ImportErrors, surely now he can get into music creation?
Yes, but not really. Instead of working with sheet music, scores, piano roll or the ubiquitous MuseScore, Sam now has to do all of his composing and idea generation like this:

Lovely. I can’t even tell if that’s Twinkle Twinkle anymore — if Sam actually changed the name from all_star to twinkle_twinkle, I doubt I would have been able to tell the difference. It’s pretty clear why this isn’t effective for any musician.
Poor Sam.
Where’s the disconnect?
Obviously somewhere along the line from research to user there’s a gap, and I’d argue it’s more than a gap. It’s the end of the line. The research has progressed far enough to release the tools for developers, but there isn’t that same level of progress in packaging and delivering the service to anyone that cares — and the vast majority of musicians won’t because of all the boilerplate.
A great example of this disconnect is Onsets and Frames, which I wrote about last year. I know so many musicians that would absolutely love the tool, but it’s just not accessible, and Onsets and Frames is actually one of the most accessible right now. Through this web-app, you can (in theory) upload any piece of music (piano preferred) and have it transcribed (i.e. put into MIDI).
When I found out about this, I was through the roof. So much of my time was spent struggling to find good transcriptions or struggling to transcribe music myself. I couldn’t wait to try it!
I uploaded a piece, closed all my other tabs and waited anxiously. I waited quite a while. It turned out that the browser “lost context” about 2 minutes in, and after that it just stopped. After doing some digging, looking in the console and analyzing my computer resources, I came to the conclusion that my Intel Integrated Graphics Card was just not cutting it (even though only 2.5/4 GB of GPU RAM was actually used).
Now this specific problem is technical in nature, and given time would certainly be fixed if it were an actual project. However, as of right now, it’s just a Demo; these are just sketches, fragments of what could be in the future.
With care, these tools can and have succeeded
When care is put into the designing the UI/UX and optimizing accessibility, these tools have made a big impact.
Case in point: the ML Bach Google Doodle.
If you’re not a musician, then chances are you are, at best, marginally aware of what this was. But for me, my musician friends and music content creators this was a big deal.
For the uninitiated, this Google Doodle was released in celebration of Johann Sebastian Bach, hailed by many as the one of the best composers of all time. He was very well known for his chorales and chorale harmonization, where he took a simple melody and made into 4-part SATB beauty.
This was extraordinarily well-received across the world (albeit with a limited “usefulness”), and it brought about joy in musicians across the world. The web-app received over 50 million queries, the “harmonize” button was clicked over 55 million times, and users spent, collectively, 350 years experimenting with the web-app.

While the ML behind it is deliciously interesting (maybe I’ll write about it…), the product was simple and accessible. Yet it was still powerful enough for anyone looking to actually harmonize like Bach did (I know I put a lot of my music theory homework through it). This is a true labour of love, and it proves that with the right design these tools will be much better used.
Here’s the key though: this is just the beginning. In terms of actual applicability, it’s use case is limited and specific. Unless I’m really having trouble with harmonizing a chorale (something that I’m better at than the Doodle anyway), there’s little to no reason I would use this outside of playing with the new tool.
Case study 2: Magenta Studio
Magenta Studio is the perfect example of what an AI-powered music creation workflow for musicians could look like. Magenta Studio is a collection of (as of now) 5 music creativity tools designed for musicians. They are available either as standalone apps or as plugins to the ever-popular Ableton Live DAW (Digital Audio Workstation).
The tools are powered by Magenta.js models, which are in turn powered by Tensorflow.js. Tensorflow.js is used to train, run and deploy models in the browser, and takes advantage of GPU acceleration without the user needing to install GPU drivers like CUDA. Magenta Studio, on the other hand, is not run in a web browser — it was built using Electron. Electron allows all the Magenta.js models to be run locally as an app!
The 5 tools are:
Continue
This system is powered by Magenta’s MelodyRNN. Using LSTMs (Long Short Term Memory network, a type of RNN), it can extend a given input melody! For more information on RNNs, you can check out my article here, but here’s a quick rundown.
RNNs are neural networks built for analyzing sequential data like audio. They are built on how we as humans think — we don’t start each thought from scratch. When we write, we write word-by-word, and each word is intensely linked to those before it — our thoughts are persistent. Traditional neural networks can’t do this.
Recurrent neural nets address this by looping the network. This can seem confusing, but hold tight.

Each cell in an RNN is like its own network, and if we unroll these cells they form a long chain of the same network. The networks pass inputs along the chain.
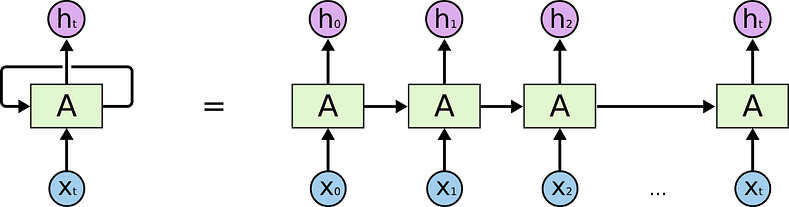
This allows RNNs to use past information to inform current decisions, making them very good at sequential tasks like predicting words, sentences and speech recognition.
MelodyRNN leverages this and treats music like a language (which it of course is!). It turns the generation problem, which is unsupervised in nature, and turns it into a supervised problem by tasking the network to instead predict the next note in a sequence. It predicts the next note, then the next, then the next, until it has extended the melody enough!
Note: this is only how their “basicRNN” model works. The Magenta team have made various improvements including implementing lookback features, attention and many others.
Generate
The generate model is similar on the surface to the continue model, except it doesn’t need an input sequence — it simply generates an entirely new melody of a given length.
But RNNs need past input to inform predictions!
Exactly. This component doesn’t use RNNs for precisely that reason. Instead, this tool makes use of the MusicVAE model, a type of Variational Autoencoder (VAE).
This model takes advantage of what are called “latent spaces”. To understand these, an example is super helpful. Here’s a great one from a paper published by people at Google Brain.
Say you want a neural network to create entirely new fonts. Let’s assume each letter is 64×64 pixels. That would mean a whopping 4096 parameters would be needed to describe a single letter. However, a generative model offers a much simpler solution by instead having only 40 latent space dimensions to describe the font.

This class of latent space models express extremely high-dimensional data in a lower-dimensional. For the font example, there are 40 dimensions or “parameters”, and together they map the font, which originally would have required 4096 parameters. The low-dimensional data are called “latent variables”, and they are best conceptualized as high-level representations of the font, melody, human etc.
In essence, these models train on many examples and “practice” mapping the latent variables to their corresponding high-dimensional data. They are trained to generalize and abstract what makes a font, and using that they can generate a font for any possible combination of latent variables.
Latent spaces need to have 3 qualities:
- Expression
Any real-life example can be mapped to the latent space.
- Realism
Any point in the latent space represents as realistic example.
- Smoothness
Points close to each other in the latent space produce similar results.
Music is, obviously, high-dimensional data. Considering only monophonic (one note at a time) piano melodies, at any given time step exactly one of the 88 keys can be pressed down or released, or the player may rest. That’s 90 possible events (88 key presses, 1 release, 1 rest). Ignoring tempo and limiting rhythm to 16th notes, there are exactly 90³² possible groups of 2 measures of 4/4 music! Extending that to 3 measures, we get 90⁴⁸ possible melodies — that’s over 6 quadrillion times the number of atoms in the universe!
Clearly we can’t just account for every possibility, but it should be obvious that most of these sequences are unmusical — they jump from extremely low to extremely high. This is a perfect use case for latent space models!
MusicVAE uses a type of latent space model known as an autoencoder (AE). Essentially an autoencoder builds a latent space of a dataset by learning to compress each example (encoding) and then reproducing each example from that compressed form (decoding).

However, this creates “holes” where not all the points in the latent space map to realistic examples. This foregoes the “realism” requirement. The way Magenta gets around this is by using variational loss. For more details and examples, check out their blog post.
Interpolate
Using MusicVAE, this extension lets composers smoothly interpolate between 2 melodies or drum grooves!
By definition, any 2 melodies will each have a corresponding point in the latent space. Let’s think about it spatially: MusicVAE essentially connects these 2 points with a vector and takes a certain number of “steps” along that vector. Different numbers of steps are different “ratios” of mixing between the 2 melodies.
Drumify
This tool is probably my personal favourite. It takes any rhythmic input and creates an entirely new drum groove to go along with it!
That’s so cool!
It’s based on the same architecture as MusicVAE with some key differences.

The “beat” is made up of the score and the groove. The score is the exact pattern — this is what Western music notation would dictate on sheet music. This rhythm is quantized, or snapped to the grid. The groove is the all the velocity (volume — accents and dynamics) and microtiming (slightly off the grid) of the beat.
This model is trained like MusicVAE, but with some differences. In addition to the MIDI patterns, the groove of a sequence is also encoded into a latent vector. This is done by training the model to reconstruct the velocity and microtiming, not just quantized MIDI.
One area (groove or score) is also masked from the encoder to optimize the model for predicting what the actual beat was given only part of the data. This makes the inputs and outputs different, technically making this a VIB (variation information bottleneck), and it helps keep all the drum beats realistic. This even results in the model adding and changing up the input, adding snare hits and omitting some hits!
The most obvious difference is that the model was trained on different data. The data was generated by professional drummers playing on an electronic drum kit with a metronome. This allows analysis of the microtiming of the drummer against the grid, as well as allowing the beats to be quantized. Many different styles were recorded, with the aim of allowing Drumify to generalize and extract the essence of groove.
Groove
Groove is very similar to Drumify, but instead of making an entirely new drum beat it instead takes a quantized pattern (the score) and “humanifies” it. The technology is largely the same, but if you want more detail be sure to check out Magenta’s blog post.
All of this proves that AI-powered tools for musicians, when they are packaged right, are powerful, helpful and extraordinary. We just need artist-focused developments like the ML Bach Doodle and Magenta Studio to bridge the gap between the developers and the musicians.
Key takeaways
- AI-powered tools for composition and songwriting are super powerful…
- But they aren’t being taken advantage of
- Using many of the tools requires:
- A great deal of preliminary setup
- Fluency of some degree in programming
- Fairly high-end hardware (for training)
- The tools are raw and unintuitive to use
- When these tools are made accessible and usable, they are hugely popular
Before you go
Thanks so much for reading this article! If you’d like to contact me, you can email me at dron.h.to@gmail.com. Stay safe!