6 Ways Automation Can Transform Your SMB’s Employee Management with Cost Efficiency
Dmytro Spilka·5 min


In the world of AI, it’s all about the inputs you can put into a deep learning model. For example, text inputs into GPT-3 that automatically summarizes your meeting notes or inputs into DALL-E that lead to amazing images.
However, I’ve found that I don’t always need such machine learning APIs.
Sometimes, I just need an API that has automatically labeled some data.
For example, I’m pretty lazy at work. I really dislike having to do everything manually, especially when it has to do with the manual labeling of data sets.
I know I can create ‘if else’ rules to label each row separately, but if my life experiences have taught me anything when I write more than 3 lines of code, I’ve probably already written a bug.
So, I had this idea why not just use machine learning to label the data automatically for me, and that’s what I exactly did except I soon realized that I needed to have this data on a dashboard for viewing.
Now what?
Then, I had this other bright idea, why not just create an API and feed it into the dashboard?
So, that’s what I exactly did.
Now, I just pretend to be working hard on spreadsheets at work while letting the magic of cloud computing do its work.
In this article, we’ll use Google Cloud Platform to create a ridiculously simple machine learning output API.
Before we start, here’s the repository if you want to take a peek at the code first.
Before we even get started on Google Cloud Platform (GCP), the first part is to do the data wrangling and get our machine learning function to work.
You can do this in any IDE such as VS Code, Google Colab, or Kaggle to name a few.
For me, we’ll be doing this on Kaggle because I feel like they are quite generous with their services and the IDE looks sleek.
We only need 2 simple libraries for this API: Pandas and Sci-kit learn.
I’ve gone ahead and decided on which algorithm I’ll use for this article.
We’ll be using Kmeans as our machine learning because we’ll only be using numeric data and wanted automatic labeling based on commonalities, which means that we only need an unsupervised machine learning algorithm for this tutorial.
import pandas as pd
from sklearn.cluster import KMeans
For this article, we’ll be using the mpg data set because it’s simple.
This data set is a about fuel conclusions in cars. You can read more about from The University of California, Irvine website.
Furthermore, I don’t want to bore and confuse you with data cleaning steps as our goal to build an ML API quickly.
In this case, I’ll be importing a CSV but more realistically, you’ll be querying from an SQL or non-SQL database, or making API calls.
df = pd.read_csv("https://gist.githubusercontent.com/omarish/5687264/raw/7e5c814ce6ef33e25d5259c1fe79463c190800d9/mpg.csv")
Let’s say what we’re working with.
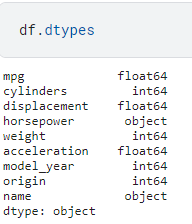
I’m not really a big fan of object fields when trying to work with a simple algorithm such as Kmeans.
Sure, we can one hot encode them but just writing data cleaning code would blow out the time it takes to read this article, so let’s just get rid of the columns we don’t need.
As mentioned, our goal is to be simple, so we’ll be removing any columns containing strings and only keep those with numeric fields.
df = df.drop(columns={"name","horsepower"})
We’ve got some integers in the data set we’ll turn them into numerics for consistency as well.
df=df.astype("float64")
Kmeans works by measuring the distance a data point has to another point. Data points close to each other make a cluster. This distance is measured by euclidian distance. Basically, imagine the hypotenuse of a triangle and that’s the distance. You can learn more from the Wikipedia article here.
You can set the number of clusters in the algorithm and if you want the outputs to be the same depending on the random state you start with. You can read more about sci-kit learn’s implementation of kmeans here.
kmeans = KMeans(n_clusters=5, random_state=0).fit(df)
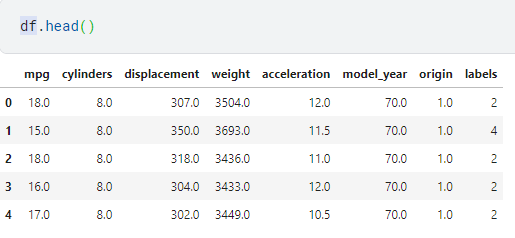
Now we have labels, so all we need to do is attach them to our data set. These are basically the clusters under which each row of data falls into.
df[ 'labels' ]=kmeans.labels_
Here’s how the results appear as a data frame.
Now, that we have a dataset we can API out, all we need to do is transform the data into JSON so that it can be easily interpreted by other systems.
result = df.to_json(orient="records")
Here’s how the results appear as JSON.

And, just to finalize everything, we’ll wrap it all into a function. This is necessary when we put out code into production.
def function(request):
import pandas as pd
from sklearn.cluster
import KMeans df =
pd.read_csv("...")
df = df.drop(columns={"name","horsepower"})
df=df.astype("float64")
kmeans = KMeans(n_clusters=5, random_state=0).fit(df)
df[ 'labels' ]=kmeans.labels_ result =
df.to_json(orient="records") return(result)
This will create a little text file that will help you tell Google which packages are required.
pip3 freeze > requirements.txt
If done correctly, the end results should look something like below.
pandas==1.4.3
scikit-learn==1.1.2
I’m not affiliated with Google Cloud Platform, so trust me I’m not selling anything here. As a matter of act, for this tutorial, you probably could even use AWS or Azure if you would like to but I’m GCP supporter.
The first step is to set up a GCP account. You can do so here and follow the instructions on how.
Google Cloud Functions is basically a serverless platform that allows you to run your own functions in the cloud. This is mostly used for building apps and is triggered by HTTPS requests.
In this case, we’ll use it for some simple machine learning.
Use the GCP search bar to find Cloud Functions.

If you want to know more about cloud functions, you can read about it here.
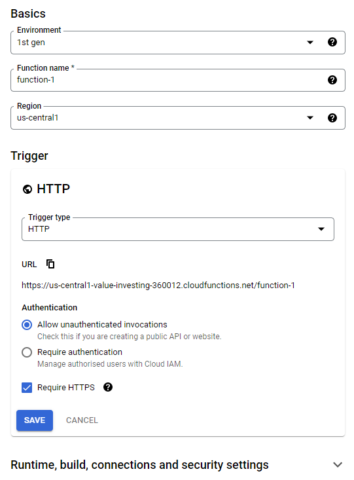
For our purposes, there’s not much to configure. GCP generously gives 2 million free invocations each month, and even then, there doesn’t seem to be many limitations on how you’re supposed to configure the function before being charged.

But, for our purposes, I like to keep the region as US-central 1 to avoid hidden costs. US-central 1, US-east 1, and US-west 1 primarily have free features, so I tend to stick with these regions.
Furthermore, I’ve changed authentication to ‘Allow for unauthenticated invocations’ because for this experiment, I’m rather too lazy to set up security. (I know. Not good cybersecurity practices!)
That’s pretty much all there is to it.
Now, we’re at the create function page.
Our function is actually wrapped around a flask function, so we don’t need to do a configuration to set up our code as an API. Google does this automatically.
All we need to do is define the function we’ll be using. Here are the steps:

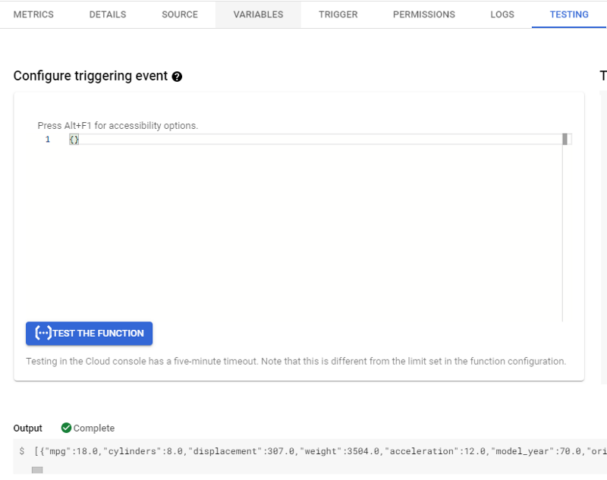
Now, just click on create, wait and test the function.
Navigate to the testing tab, click on “test function” and see if you agree with the outputs.
My output looks good, so I’m happy.
As you can tell, this is pretty easy.
You don’t even need to know how to do front-end programming or even cloud computing to get started. As long as you know how to build a Python function, then you’re all good.
What I do have to point out is that this is we’ve just built an API that will make automatic API calls, transform the data and send the data off as JSON. This is a very specific one-way path.
However, if want to do something a bit more complex, we’ll save that for a future article.
Here’s the GitHub repository if you want to try it out for yourself. I’ve already wrapped the code around flask, to mimic how it should act as it would in Google Cloud Platform. Just make sure you run it in something like VSCode rather than a Juypter Notebook as the script will open up a separate webpage.
I'm a data analyst who enjoy reading annual reports. My hobbies include exercise, cooking and being a well rounded dad. I work as an analyst in the higher education sector in Australia but my passion is in investing. I used to believe that data could solve everything but it wasn't until I read Charlie Munger's "Poor Charlie's almanack" that I realised that I've been thinking in silos all this time and I really needed to expand my experiences and reading. What concerns me about life is making silly choices and following the trend aimlessly. I believe in critical thinking and serving others as I would like to be served.