Your Model Doesn’t Have a Bias Problem. It Has a Reference-Class Problem.

Why decision systems keep misreading the individual — and an experiment that shows the mechanism
In 2019, Ziad Obermeyer and colleagues showed that a widely used U.S. healthcare algorithm was systematically underestimating the needs of Black patients (Science, 2019). The model wasn’t malicious. The data wasn’t even wrong. The flaw was subtle.
Actually, it was using data that faithfully reflected an unequal healthcare system. The flaw was subtler, and more consequential: healthcare cost had been treated as a stand-in for healthcare need. Because equivalent illness had historically generated lower spending for Black patients, the algorithm interpreted them as healthier than they were. Reformulating the target away from cost increased the share of Black patients selected for additional care from 17.7% to 46.5%.
We tend to name this kind of failure with one heading: bias. Often that’s right. But I’ve come to think the label sometimes hides something more basic, and more general — a problem about what the system compares each individual against.
Obermeyer’s case is the famous version of one failure mode: the wrong proxy. Cost stood in for need, and the stand-in betrayed the people it was meant to represent. There is a quieter sibling that gets far less attention — not the wrong proxy, but the wrong reference class.
A reference class is the population you compare a single case to in order to interpret it. The reference-class problem is old enough to have troubled philosophers of probability long before it troubled data scientists. It is what happens when you pick a class that doesn’t actually contain the relevant information about the individual, and then mistake the comparison for a fact about them. The distinction matters because the two failures have different cures: a proxy problem is the wrong thing measured; a reference-class problem is the wrong population measured against. The data can be flawless and the proxy well chosen, and the system can still misread you — because it is holding you up against a crowd you don’t belong to.
Once you start looking for it, the reference-class problem emerges wherever a decision system encounters an individual. A lab result sits inside the population “normal range,” so the dashboard turns green — even when, for this patient, it is a large and fast departure from their own baseline; this is exactly why precision medicine is moving toward adaptive, individualized reference ranges. A loan applicant is scored against a risk class of people who resemble them on a handful of features — fine for the median member, wrong for the atypical one the cohort describes badly. A recommender serves “users like you,” a reference class by construction, reliable on average and least reliable for the person who isn’t well described by their nearest cohort. In each case the algorithm is doing its job. The error is upstream, in the choice of who each individual is compared to.
Dogs happened to be a place to isolate the mechanism: same detector, same data, same false-alarm rate — only the reference frame changes.
Companion-animal monitoring judges a dog’s behavior against its breed average. But an ancestry-inclusive study of more than two thousand dogs found that breed explains only about 9% of the behavioral variation between individuals (Morrill et al., Science, 2022). A dog can be perfectly normal for its breed and abnormal for itself — and the reverse. The one that is quietly declining stays inside the breed band, invisible, because it is being compared to a population instead of to its own history. The trap appears there with unusual clarity, and — unlike in human health — you can build a controlled version of it with known ground truth.
So I built the comparison directly. Two decline detectors, identical except for one thing: the reference frame — each animal compared to its own first 56 days, versus the pooled first 56 days of the cohort. The decline is injected and known; no real animals, sensors, or clinical outcomes are involved. This is not a validation. It is a test of whether the mechanism behaves as the theory predicts.
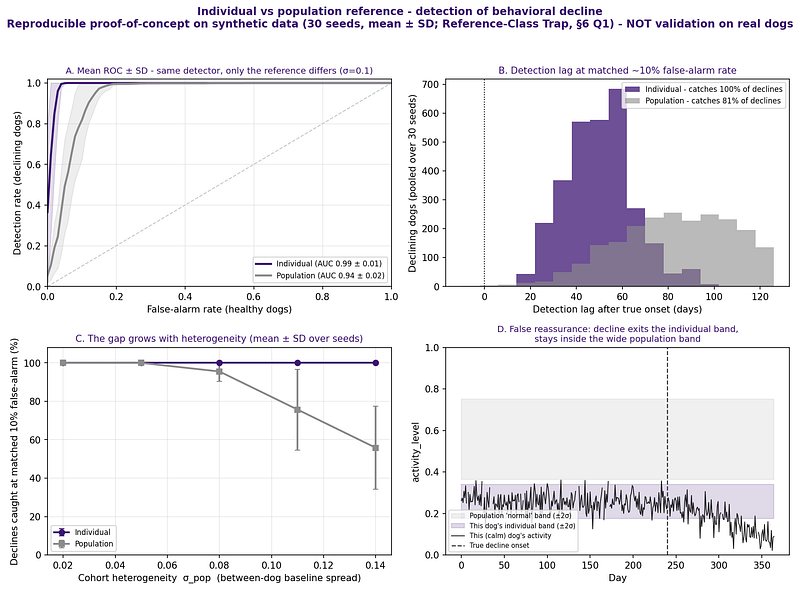
Figure 1. Individual- vs. population-referenced detection on the same synthetic behavioral data, swept across rising cohort heterogeneity (30 seeds; mean ± SD). A controlled mechanism test — the decline is injected and known — not validation on real dogs.
Figure 1 shows that it does — and conditionally, which is the honest result. When the synthetic cohort is nearly homogeneous, the population reference does as well as the individual one. But as between-individual baseline heterogeneity grows, the population band widens, and genuine individual declines stay inside population “normality” while clearly exiting the animal’s own band. Across thirty seeds at a matched ~10% false-alarm rate, the individual reference catches every injected decline; the population reference falls from full detection toward roughly half as heterogeneity grows. Same detector, same data, opposite outcome — decided entirely by the reference frame.
I want to be precise about what this does and does not show, because the temptation to overclaim is exactly the disease under discussion. It does not prove the approach works on real animals. It shows three things at three different strengths: the premises are supported by existing science (individuals vary; population labels are weak proxies for them); the mechanism is reproducible under controlled conditions; and the real-world comparative claim — individual baseline versus population reference, on real subjects, for real events — remains open and testable. That is a more honest, and ultimately stronger, position than the absence of evidence.
The generator, the detection pipeline, and the figure are open and reproducible: github.com/labs-barkley/barkley-reference-architecture (archived on Zenodo, 10.5281/zenodo.20369864), with the full conceptual paper at 10.5281/zenodo.20756552.
Decision intelligence has spent a decade getting better at patterns. The harder question is no longer whether a model can find a pattern — it can — but whether it is looking at the right reference frame while it does. Most of our debates about fairness are about the data or the proxy. The reference class is the quieter knob, and frequently the decisive one: hold the algorithm fixed, change only what each individual is compared against, and the same system can flip from missing the person to seeing them.
The problem is not that AI sees patterns.
The problem is that it sometimes sees the wrong reference frame.
And the fix, across every one of these domains, points the same way: where it matters most, the right thing to compare an individual to is usually the individual’s own history.
Disclosure: The research question, experimental design, analysis, and conclusions are mine. AI was used for translation and editorial drafting. I disclose that use openly. I’m proudly AI-assisted.
Trading signals powered by data
Real-time institutional flow data and trading signals for serious investors.
Explore DataDrivenAlpha →Turn this article into a video
Instantly repurpose any DDI article into a professionally produced short-form video.
Try DDI Media →I am the founder of Barkley AI and independent researcher. I write about decision intelligence and the reference-class trap: systems that judge each individual against a population average instead of against themselves — in health, credit, recommendation, and the companion-animal work where I test the mechanism. Individual over population, always. Proudly AI-assisted.