You're Not Optimising Your Campaigns. You're Reacting to Noise

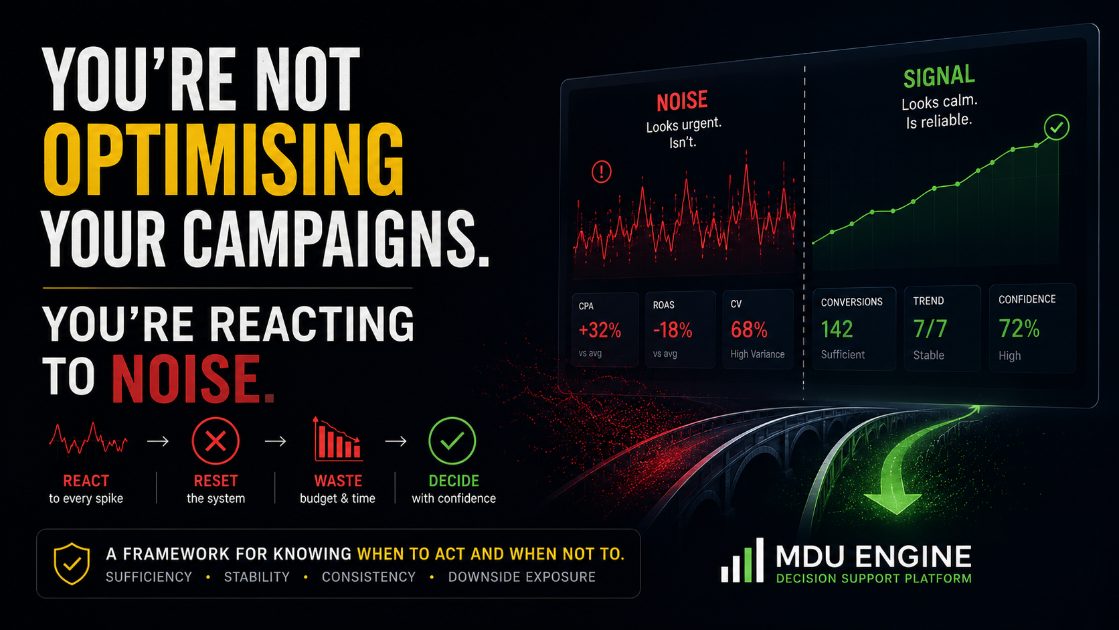
There is a distinction that most performance marketing teams never formally make.
The distinction between a signal and noise.
Not in theory, most practitioners understand the concept. But in practice, in the daily rhythm of dashboards, alerts, and budget decisions, the line between the two collapses almost entirely. Every movement becomes a signal. Every signal demands a response. And the system, the tools, the culture, the incentive structure rewards the response.
This is not optimisation. It is reactive intervention dressed in the language of data-driven decision-making.
And it is costing teams more than they realise.
The Illusion of Control
Performance marketing is built on a feedback loop: observe, decide, act. The assumption embedded in that loop is that faster feedback means better decisions. Shorter cycles. Quicker corrections. More control.
That assumption is correct in one specific condition: when the data you are observing is reliable enough to act on.
In most real campaign environments, that condition is not met.
Data arrives incomplete. Attribution windows are still open. Conversion volumes are too thin to draw statistical conclusions. Platform algorithms are mid-calibration. External variables seasonality, competitive activity, macro shifts are introducing variance that has nothing to do with campaign performance.
In these conditions, the feedback loop does not produce better decisions. It produces more decisions, made faster, on data that is not yet ready to support them.
The result looks like optimisation. It produces the appearance of control. But underneath, it is systematic noise-chasing and it compounds over time in ways that are genuinely difficult to untangle.
What Noise Looks Like in Practice
Consider a campaign running on a major paid platform. It enters a standard learning phase, the period during which the algorithm calibrates delivery, audience matching, and bid strategy based on early conversion signals.
During this phase, performance metrics are inherently unstable. CPA fluctuates. ROAS is unreliable. Impression share oscillates as the system tests different audience configurations.
A practitioner monitoring this campaign sees the CPA spike on day three. The dashboard turns red. The instinct, trained by years of performance culture, is immediate: adjust the bid, pause the ad set, reallocate to a different creative.
So they act.
What they have just done is intervene in a system that was functioning correctly. The instability was not a failure, it was the expected behaviour of a calibration process. The spike was not a signal of structural underperformance. It was noise, produced by a system doing exactly what it was designed to do.
The intervention resets the learning phase. A five-day calibration becomes ten days. The team interprets the ongoing instability as evidence that more optimisation is needed. More adjustments follow. The cycle continues.
At no point does anyone ask the prior question: was the data ready to be acted on at all?
The Question Nobody Formally Asks
This is the structural gap that sits at the centre of most optimisation workflows.
The systems are built to answer: what should we do?
Nobody builds infrastructure to answer: should we do anything yet?
These are categorically different questions. The first assumes the data is decision-ready and asks for direction. The second interrogates that assumption before any direction is given.
In statistics, this distinction is fundamental. You do not draw conclusions from a sample that has not reached sufficient size. You do not call a trend from three data points in a volatile series. You do not act on a signal before establishing that it is, in fact, a signal.
In clinical trial design, this principle is so well understood that entire regulatory frameworks exist to enforce it. No intervention is approved on insufficient data, regardless of how promising the early results appear.
In financial risk management, position changes are evaluated not just on the basis of what the market is doing, but on the reliability of the signal being observed and the downside cost of acting prematurely.
Performance marketing operates in environments that are statistically comparable in complexity. The data is noisy. The observation windows are short. The signals are ambiguous. The cost of premature intervention is measurable and often significant.
And yet the infrastructure to ask whether the data is ready simply does not exist in most operational analytics stacks.
Four Conditions That Determine Decision Readiness
When I began mapping this failure pattern systematically across different campaign environments, platforms, and team structures, four conditions emerged consistently as the determinants of whether a data point was actually ready to be acted on.
Sufficiency. Is there enough volume in the observation window to draw a statistically reliable conclusion? A CPA calculated on twelve conversions is not the same as a CPA calculated on twelve hundred. Both might breach the same alert threshold. Only one carries inferential weight.
Stability. Is the metric moving in a consistent direction, or oscillating? A metric that has declined steadily across seven consecutive days tells a different story than one that has fallen, partially recovered, fallen again, and recovered again. The first may represent a trend. The second is almost certainly noise.
Consistency. Are independent indicators corroborating the primary signal? A CPA increase accompanied by stable CTR and flat CPM suggests one interpretation. The same CPA increase accompanied by declining CTR and rising CPM suggests something entirely different. Context changes the signal. Ignoring context produces misinterpretation.
Downside exposure. What is the cost of intervening if the data is not ready? In learning-phase campaigns, that cost is high intervention resets the calibration cycle and extends instability. In mature campaigns with stable baselines, the cost of waiting may be higher than the cost of acting. The evaluation needs to be context-sensitive, not applied as a universal rule.
When all four conditions are met, the data is decision-ready. When they are not, the correct output is not a different recommendation, it is a recommendation to wait.
Why "Wait" Is the Hardest Output to Engineer
There is a behavioural dimension to this problem that is worth naming directly.
In performance environments, inaction is culturally coded as negligence. If a metric is moving in the wrong direction and nothing is done, the implicit assumption is that the team is not paying attention. Action signals competence. Restraint signals passivity.
This creates a systematic bias toward intervention that exists independently of what the data actually suggests. Teams act not because the data demands action, but because the environment demands action.
Decision-support systems that can only produce action recommendations reinforce this bias. They give practitioners a way to act quickly and justify it analytically. What they do not provide is a way to justify not acting even when not acting is demonstrably the correct decision.
An effective decision layer needs to produce restraint outputs with the same rigour and explainability as action outputs. The practitioner who decides to hold position needs to be able to point to a structured evaluation that supports that decision. Otherwise the organisational pressure to act will always override the analytical case for restraint.
This is not a small design problem. It is the central design problem in operational decision-support and it is almost entirely unsolved in the tools that practitioners currently use.
What Changes When You Evaluate Before You Act
The practical implication of this framework is straightforward, even if the implementation is not.
Before any optimisation decision is made, the data supporting that decision should pass through an evaluation layer that assesses sufficiency, stability, consistency, and downside exposure. Only when that evaluation produces a positive result, when the data is genuinely ready should any action be considered.
In environments where data is clean, high-volume, and stable, this layer adds minimal friction. The evaluation is fast, the signal is reliable, and the action is justified.
In the environments where most practitioners actually operate, volatile signals, short observation windows, incomplete attribution, overlapping variables, this layer is not a nice-to-have. It is the part of the decision infrastructure that is almost always missing.
The output of that layer is not always an action recommendation. Sometimes it is a hold. Sometimes it is an explicit refusal to decide a structured acknowledgement that the data is not yet ready, and that intervening now would introduce more risk than it resolves.
That output is often the most valuable thing a decision-support system can produce. Not because it is always correct to wait, but because it forces the question that the existing infrastructure systematically avoids:
Is this data actually ready to be acted on?
The Real Cost of Noise-Chasing
Teams that operate without this evaluation layer are not making bad decisions. They are making decisions in good faith, on the best data available, using the best tools available.
The problem is that the tools are not designed to distinguish between data that is ready and data that merely appears to be ready. They optimise the observation. They accelerate the action. They do not evaluate the gap between the two.
Over time, this produces a specific and measurable pattern: campaigns that are perpetually mid-adjustment, metrics that are difficult to interpret because the baseline keeps shifting, teams that are busy but unable to determine whether their activity is producing outcomes or obscuring them.
This is the real cost of noise-chasing. Not individual bad decisions, but a systematic erosion of the signal-to-noise ratio in the data environment itself caused, ironically, by the act of trying to optimise it.
Solving this requires infrastructure that most teams do not currently have: a decision layer that sits between observation and action, asks whether the data is ready, and produces structured outputs including the output that says wait.
That infrastructure is not complex to conceptualise. But it requires a shift in how we think about what optimisation systems are actually for.
They are not for producing recommendations. They are for producing reliable decisions.
Those are not the same thing.
Satish Saka is the founder of MDU Engine, a decision-support platform that evaluates optimisation readiness before any action is taken. His research on decision-support frameworks under uncertainty is published in JETIR and has received independent academic evaluation from KL University. He writes about decision systems, signal reliability, and the infrastructure required to make data-driven decisions reliably. Reach him at satish@mduengine.com or mduengine.com.
Satish Saka is a practitioner working on decision-support systems in analytics environments. He developed MDU Engine, a public decision-support platform designed to evaluate data readiness, confidence stability, and downside risk before optimisation actions are taken in performance-driven systems. His work focuses on decision-making under uncertainty, validation-gated optimisation, and human-in-the-loop analytics architectures. He writes on decision intelligence, applied analytics, and responsible automation in data-driven domains.